



#250 - Sức mạnh của DynamoDB
Tìm hiểu thêm về sức mạnh của DynamoDB qua một use case cụ thể

📻News
( by steven.do87 & nt9)
Gpt-4 Developer livestream
Greg Brockman của OpenAI đã trình bày các tính năng ấn tượng mới của GPT-4 trong một buổi phát trực tiếp vào ngày 14/3. GPT-4 có thể phân tích hình ảnh và văn bản, lập trình, tóm tắt văn bản và viết lời bài hát. GPT-4 cũng đối mặt với các vấn đề về chất lượng dữ liệu, đánh giá và đạo đức.
Fake ChatGPT Chrome Extension Hijacking Facebook Accounts for Malicious Advertising
Một extension mở rộng mạo danh ứng dụng ChatGPT mang tên "Quick access to Chat GTP" hỗ trợ trình duyệt Chrome đã được cài đặt hơn 2000 lượt / ngày từ 03/03/2023 và tải về từ Chrome Web Store, đã được phát hiện có khả năng chiếm quyền điều khiển tài khoản Facebook, đây xem như một phương thức mới mà tội phạm mạng áp dụng trong việc phân phối malware độc hại.
TikTok whistleblower claims US data privacy efforts are seriously flawed
Những nỗ lực của TikTok nhằm giải quyết những lo ngại về quyền riêng tư dữ liệu của Hoa Kỳ có thể xuất hiện lỗ hổng. Một nguồn tin tố giác đã trao đổi với The Washington Post cho biết kế hoạch bảo vệ dữ liệu của người dùng Mỹ, Project Texas, của mạng xã hội Tiktok đã có những sai sót lớn. Cựu thành viên nhóm Trust and Safety tuyên bố sáng kiến giải quyết vấn đề về quyền riêng tư dữ liệu trị giá 1,5 tỷ USD vẫn sẽ cho phép TikTok kết nối với Toutiao của công ty mẹ ByteDance, một ứng dụng tin tức nổi tiếng của Trung Quốc. Liên kết đó về mặt lý thuyết có thể cho phép Trung Quốc truy cập dữ liệu của Hoa Kỳ.
Ubuntu Lunar Lobster could be the surprise hit of 2023
Thay đổi lớn nhất đối với Ubuntu 23.04 đến từ trình cài đặt nhưng chủ yếu chỉ là cải tiến về vẻ thẩm mỹ bên ngoài (mặc dù nó đã được viết lại hoàn toàn bằng Flutter). Hiệu suất và khả năng sử dụng đóng một vai trò rất lớn trong sự thành công của một hệ điều hành và Lunar Lobster đã và đang nắm chắc cả hai yếu tố đó. Đây là bản phát hành hàng ngày và vẫn chưa đạt đến giai đoạn beta của chu kỳ phát hành. Tình trạng hiện tại của Lunar Lobster khá ổn định, đặc biệt là đối với bản phát hành trước phiên bản beta. Tuy nhiên, nếu có ý định sử dụng thực tế, thì vẫn nên chờ cho đến ngày phát hành chính thức vào ngày 20/4/2023.
Google Service Weaver Enables Coding as a Monolith and Deploying as Microservices
Google vừa phát hành Service Weaver, là một open-source framework hỗ trợ xây dựng và triển khai các ứng dụng phân tán. Framework được phát triển dựa trên ngôn ngữ Go, bao gồm một bộ thư viện lập trình cho phép viết các ứng dụng dưới dạng các module nhị phân riêng lẻ. Các thành phần còn lại là một bộ các deployer cho phép thiết lập cấu hình runtime topology và cho phép ứng dụng hoạt động trên môi trường cục bộ hoặc trên môi trường cloud.
📰Những bài viết hay
Dynamodb use case
(by n^4)
Được giới thiệu lần đầu tiên trong một paper ở hội nghị ACB Symposium on Operating Systems Principles (SOSP) năm 2007, kể từ đó đến nay kiến trúc của DynamoDB đã trải qua nhiều biến đổi và trở nên ngày càng linh hoạt, mạnh mẽ hơn với các tính năng như tự động mở rộng, tùy chỉnh độ nhạy cảm về chi phí, tối ưu hóa truy vấn, cơ chế xác thực và bảo mật, ...
Để hiểu thêm về sức mạnh của DynamoDB, mời các bạn cùng tham khảo series bài viết trên blog của AWS chia sẻ thông qua quá trình thiết kế một use case cụ thể được yêu cầu bởi Accenture Federal Services.
Trong use-case này, Accenture Federal Services đang cần thiết kế một dịch vụ tra cứu siêu dữ liệu địa chỉ IP. Bộ dữ liệu của họ bao gồm hàng trăm ngàn phạm vi địa chỉ IP, mỗi phạm vi có một địa chỉ bắt đầu (như 192.168.0.0), một địa chỉ kết thúc (như 192.168.10.255) và các siêu dữ liệu liên quan (như chủ sở hữu, quốc gia, các quy tắc bảo mật áp dụng, v.v.). Truy vấn của họ cần chấp nhận một địa chỉ IP, tìm phạm vi chứa nó và trả về các siêu dữ liệu.
Accenture Federal Services muốn biết:
DynamoDB có hoạt động tốt cho dịch vụ tra cứu này hay không?
Thiết kế bảng nào sẽ hoạt động tốt nhất?
Thiết kế nào sẽ hiệu quả nhất về thời gian chạy, chi phí và khả năng mở rộng?
Số lượt tra cứu tối đa mỗi giây mà DynamoDB có thể đạt được?
Họ cũng quan tâm rằng trường hợp sử dụng của họ không có vẻ như là một trường hợp sử dụng cổ điển của DynamoDB, vì không có khóa phân vùng rõ ràng. Họ muốn biết nếu điều đó sẽ hạn chế hiệu suất hay không?
Serie ba bài viết này sẽ giúp trả lời các câu hỏi nên trên:
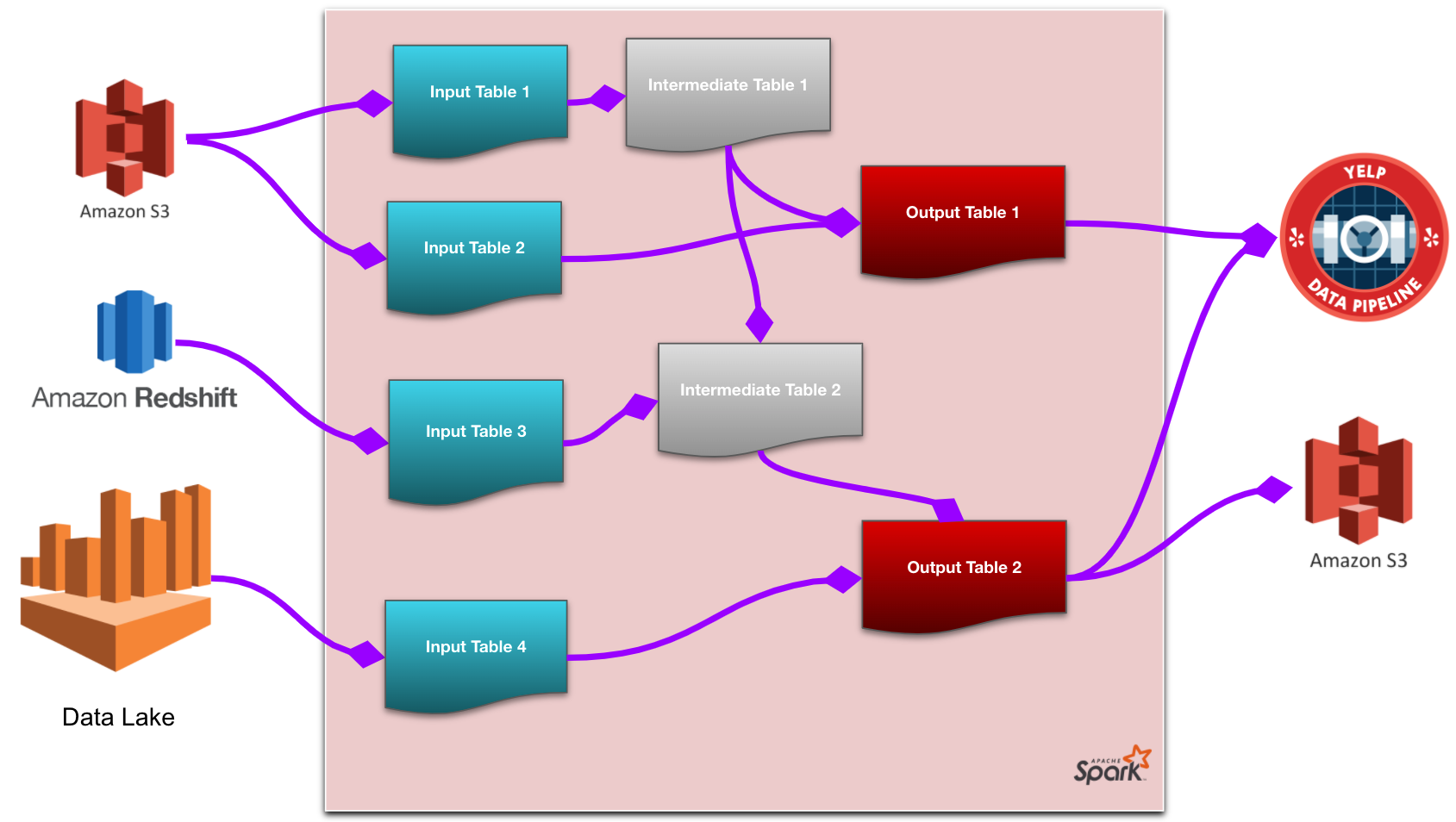
Spark Data Lineage
(by steven.do87)
Bài viết giới thiệu về cách thức mà giải pháp Spark-Lineage được phát triển và áp dụng tại Yelp nhằm hỗ trợ việc lưu vết (track) và thể hiện trực quan (visualize) cách thức data được xử lý, lưu trữ và transfer giữa các services trên hệ thống tại Yelp. Tại Yelp, Spark được xem là công cụ đắc lực trong việc xử lý dữ liệu từ mọi góc độ, từ việc thu thập các bài đánh giá cho đến phân tích báo cáo về việc tối ưu hóa công cụ tìm kiếm theo từng vùng.
Các kỹ sư tại Yelp đã phát triển một giải pháp Spark-ETL với với phần lõi là Spark nhằm cung cấp các high-level API để thực hiện xử lý các khối dữ liệu (batch jobs) và đơn giản hóa việc sử dụng Spark, giúp các kỹ sư tại Yelp tiết kiệm được thời gian, và thuận tiện hơn trong quá trình debugs và duy trì vận hành các Spark jobs. Với một hệ thống xử lý và truyền tải dữ liệu giữa hàng trăm các microservice và lưu trữ trên nhiều định dạng khác nhau tại nhiều kho lưu trữ dữ liệu khác nhau như: Redshift, S3, Kafka, Cassandra,vv..
Vấn đề này dẫn đến việc hiểu rõ các liên kết phụ thuộc (dependencies) giữa các services này rất khó khăn, và việc thay đổi các cấu trúc hệ thống có thể gây ảnh hưởng hàng loạt.
Để khắc phục những vấn đề kỹ thuật này, các kỹ sư tại Yelp đã phát triển giải pháp Spark-Lineage nhằm cung cấp một công cụ trực quan theo dõi hành trình của dữ liệu, bao gồm tất cả các bước từ nguồn đến đích, cùng với các thông tin chi tiết về nơi dữ liệu di chuyển, và cách xử lý cũng như lưu trữ của dữ liệu tại mỗi bước, kết hợp với Spark-ETL cho phép người dùng có thể theo dõi vòng đời của dữ liệu (life cycle of data) thông qua các nền tảng quản trị dữ liệu (data governance).
Cùng khám phá chi tiết cách thức tiếp cận và xử lý vấn đề trong quá trình phát triển giải pháp Spark-Lineage cùng các kỹ sư của Yelp thông qua bài viết.
👨💻Góc lập trình
(by ndaadn and phucnh)
Đề ra tuần này: Top k Frequent Elements
Cho một mảng số nguyên nums và một số nguyên k, trả về phần tử xuất hiện thường xuyên thứ k trong mảng. Ví dụ: Input: nums = [1,1,1,2,2,3], k = 2 Output: [1,2]
Lời giải tuần trước: Minimum Height Trees
Thông thường ta có thể duyệt qua toàn bộ ma trận, sử dụng DFS để tìm số tập các ký tự X liền kề, từ đó xác định số tàu chiến. Tuy nhiên để ý dữ kiện Do tàu chiến chỉ được đặt ngang hoặc dọc trên biển, tàu chiến sẽ luôn có kích cỡ là 1 x k với k là chiều dài của tàu, ta chỉ cần đếm số “đầu” tàu là có thể xác định được số lượng tàu.
Thực hiện duyệt qua từng vị trí của ma trận, nếu vị trí (i, j) là một ký tự X, ta kiểm tra xem ký tự (i-1,j) hoặc (i,j-1) có phải là X hay không, nếu có thì (i,j) không phải là đầu của tàu, và ngược lại (i,j) là đầu của tàu và ta tăng biến đếm số lượng tàu lên 1.
Cài đặt tham khảo bằng Java như sau:
public int countBattleships(char[][] board) {
int ans = 0;
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[i].length; j++) {
if (board[i][j] == 'X') {
if ((i > 0 && board[i - 1][j] == 'X') || (j > 0 && board[i][j - 1] == 'X'))
continue;
else
ans++;
}
}
}
return ans;
}Độ phức tạp thời gian của giải thuật là O(MxN) với M, N là kích thước ma trận đầu vào, độ phức tạp bộ nhớ là O(1) vì ta chỉ sử dụng thêm 1 biến đếm số lượng tàu.
🛠️Code & Tools
Smithy: is a language for defining services and SDKs.
Scala-cli: is a command-line tool to interact with the Scala language.
Quotes
If it is not right, do not do it, if it is not true, do not say it.
Marcus Aurelius